![[CS182] Lecture 5: Backpropagation](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FokrXA%2FbtsG3MNDpCm%2FAU4y0zfCLrcibryGzyvpkk%2Fimg.png)
해당 글은 CS182: Deep Learning의 강의를 정리한 글입니다. 여기서 사용된 일부 슬라이드 이미지의 권리는 강의 원작자에게 있습니다.
이번 강의에서는 본격적으로 깊은 신경망(Deep neural network, DNN)에 대해 알아볼 것입니다. 먼저 머신러닝 모델을 그림으로 표현하는 법에 대해 배운 다음, 왜 깊은 신경망은 겹겹이 쌓아올린 모습을 하고 있는지를 알아볼 것입니다. 그리고 마지막으로 깊은 신경망 모델을 학습시키기 위한 역전파 알고리즘도 배울 겁니다.
모델을 그림으로 표현하기
왜 그림으로 표현해야 할까
우리는 지금까지 수학 식을 통해 모델을 표현했습니다. 하지만 데이터가 모델에서 어떻게 연산되는지 살펴보기에 수학 식은 불편합니다. 이를 위해 우리가 사용할 표기법은 계산 그래프 (Computation Graph) 입니다. 계산 그래프란 값이 어떤 순서로 연산되는지를 표현한 유향 그래프입니다.

위의 그림은 이전 시간에 배운 평균제곱오차를 표현한 계산 그래프입니다. 입력값, 파라미터, 라벨값이 표시된 노드에서 시작해 화살표대로 연산을 하면 회귀 모델의 손실값을 평균제곱오차로 구할 수 있습니다.
그렇다면 왜 수학식 대신 계산 그래프로 모델을 표현할까요? 이는 두가지 이유 때문입니다.
- 모델이 어떤 방식으로 데이터를 조작하는지 쉽게 파악할 수 있다
- 모델 가중치의 그래디언트를 어떻게 계산할지 빠르게 알아낼 수 있다
모델은 입력 데이터를 조작하는 방법에 따라 그 구조가 달라집니다. 즉, 모델의 구조를 파악한다는 것은 그 모델의 데이터 조작 방식을 알아낸다는 뜻이기도 합니다. 만약 수학식으로 모델을 표현했다면 이 모델이 다른 모델과 어느 부분이 달라졌는지, 그 부분이 어떤 역할을 할지 파악하는데 시간이 걸립니다. 하지만 모델을 계산 그래프와 같은 그림으로 표현했다면 우리는 빠르게 모델의 구조를 비교할 수 있습니다.
또 하나의 이유로 모델 가중치의 그래디언트를 계산할 때 도움이 되는데, 이는 뒤에서 자세하게 설명할 겁니다.
그럼 어떻게 그려야 할까
위에서 본 계산 그래프를 다시 보면 입력 데이터의 특성이 두개라는 것을 알 수 있습니다. 입력 데이터의 각 특성은 각각의 파라미터와 곱해진다는 것은 쉽게 파악이 가능합니다.
하지만 만약에 입력 데이터의 특성이 100개였다면 어땠을까요? 아마 아까와 같은 방식으로 그렸다면 세로로 긴 그래프가 그려질 겁니다. 모델은 단순히 입력 데이터와 파라미터를 각각 곱하는 단순한 연산을 수행하지만, 이를 그래프로 표현하면 오히려 모델의 구조를 파악하기 어려워집니다.
그렇기 때문에 모델의 계산 방식을 지나치게 자세하게 그리면 안됩니다. 모델에서 연산의 의도를 쉽게 알아볼 수 있도록 간단하게 그리는게 중요합니다. 이를 위해 써볼 수 있는 좋은 방법 중 하나가 벡터와 행렬을 사용하는 겁니다.
이번에는 로지스틱 회귀 모델을 계산 그래프로 그려봅시다. 여기서도 입력 데이터와 각 라벨 별 파라미터를 벡터로 표현해 간결하게 표현했습니다. 하지만 로지스틱 회귀 모델을 그릴 때 신경써야 하는 부분이 두가지가 더 있습니다.
그 중 하나는 'NLL(Negative Likelihood Loss)을 어떻게 그릴까' 입니다. 로지스틱 회귀 모델은 NLL을 구하기 위해 softmax를 구한 다음 그 중 정답 라벨에 해당하는 확률값만 골라냅니다. 하지만 이를 그대로 그린다면 각 라벨마다 softmax값을 구하고 이 중 하나를 구하는 그래프를 그려야 합니다. 그렇게 되면 그래프 속 노드가 많아지고 구조가 복잡해질 겁니다. 이를 해결하기 위해 NLL식을 변형하는 겁니다.
softmax 값을 먼저 구하고 log 함수를 씌우는 방법 대신 식에서 softmax 계산까지 한번에 계산해 필요한 계산 수를 줄이면 됩니다. 계산에 들어가는 연산 수가 줄어드니 계산 그래프의 모습도 나름 간결해질 겁니다. 하지만 아직 해결하지 못한 문제가 하나 더 있습니다.
우리가 로지스틱 회귀 모델의 손실값을 구할 때, 정답 라벨에 해당하는 확률만 가져와 계산합니다. 하지만 이 방식으론 벡터 연산으로 표현할 수 없습니다. 벡터 연산에서 일부만 가져오는 연산자를 직접 제공하지 않기 때문입니다. 하지만 정답 라벨값을 원-핫 벡터로 표현한다면 이를 흉내낼 수 있습니다.
원-핫 벡터란 해당하는 값의 차원만 1, 나머지는 0으로 채운 벡터를 말합니다. 이제 정답 라벨값을 원-핫 벡터로 표현하고 이를 라벨별
이렇게 이진 분류를 수행하는 로지스틱 회귀 모델을 표현했습니다. 하지만 위 그래프는 우리가 선형 회귀 모델을 그릴 때 본 문제와 비슷한 문제를 안고 있습니다. 만약 분류할 라벨 수가 100개 이상이 되면 이를 다 노드로 표현해야 할까요?
우리가 로지스틱 회귀 모델의 구조에서 보고자 하는건 데이터와 각 라벨의 확률를 계산하는 파라미터가 각각 곱해진다는 사실이지,
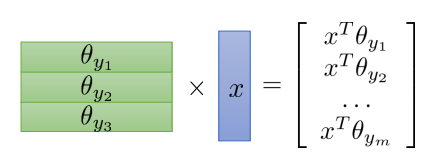
물론 이 또한 방법이 있습니다. 우리는 이 연산을 행렬곱으로 표현할 수 있기 때문입니다.
문제가 한가지 더 있습니다. 우리가 손실 함수의 연산을 간단하게 표현하기 위해 softmax와 NLL을 하나로 합쳐서 계산했습니다. 그 덕분에 그려야할 노드가 줄긴 했지만 정작 모델이 수행하는 연산이 softmax와 NLL인지 알아볼 수 없게 되었습니다. 우리가 계산 그래프로 모델을 그리는 이유가 모델의 구조를 쉽게 파악하기 위함이지, 단순히 모델의 계산 순서을 알기 위함이 아닙니다. 이러한 시각으로 볼때 우리는 굳이 softmax의 연산을 풀어 쓰지 않고 그대로 하나의 연산으로 표현하면 됩니다.
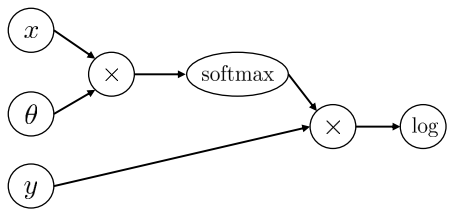
파라미터를 행렬로 그리고 softmax 연산을 하나의 노드로 그리니 이전보다 훨씬 간단하게 그려졌습니다. 무엇보다 데이터가 어떻게 계산되는지 한눈에 알 수 있습니다.
여기서 더 나아가 봅시다. 위의 그래프를 살펴보면 파라미터
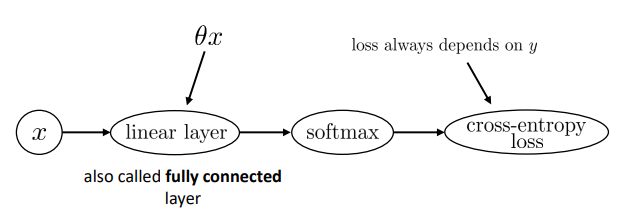
이젠 모델의 계산 그래프가 일반적인 그래프의 모양보단 일종의 파이프라인이나 합성함수를 표현한 그림으로 보입니다. linear layer나 cross-entropy loss은 다른 모델에서도 많이 쓰이기 때문에 굳이 세부 모습을 그릴 필요가 없습니다.
신경망(Neural Network) 다이어그램
많은 연구원들이 신경망 모델의 구조를 표현할 때 위의 그래프처럼 그리게 됩니다. 신경망 모델을 그릴 때 보통 입력 데이터가 어떤 함수를 어떤 순서로 지나가는지를 표현하게 됩니다. 그리고 모델을 구성하는 각각의 함수를 레이어(layer)라고 부릅니다. 정리하면 신경망 모델은 입력 데이터가 순차적으로 지나갈 여러 레이어로 구성됩니다.
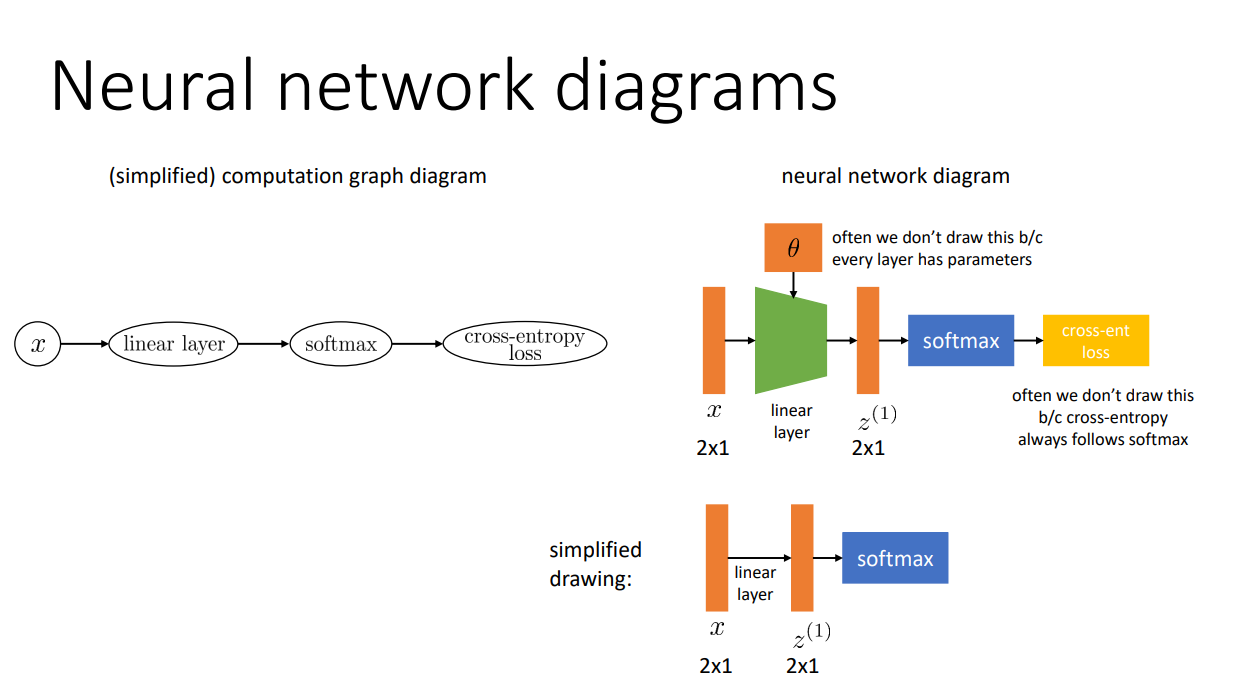
다만 실제로 논문에서 신경망을 표현하는 그림은 우리가 사용한 계산 그래프와는 조금 다른 방식으로 표현합니다. 가장 큰 특징으로는 레이어를 지나가는 입출력 데이터(
특성(Feature) 학습하기
새로운 특성을 찾아야 하는 이유

모델마다 성능이 십분 발휘되는 데이터 분포가 있습니다. 예를 들어, 로지스틱 회귀 모델은 위의 그림처럼 데이터 분포가 선형으로 분리 가능하다면 데이터 분류를 쉽게 해냅니다.
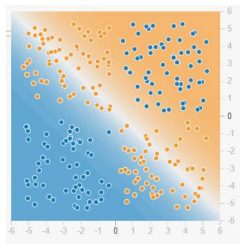
하지만 이처럼 선형으로 분리하기 어려운 데이터는 로지스틱 회귀로 분류할 수 없습니다. 그렇다면 이를 위해 새로운 모델을 개발해야 할까요?
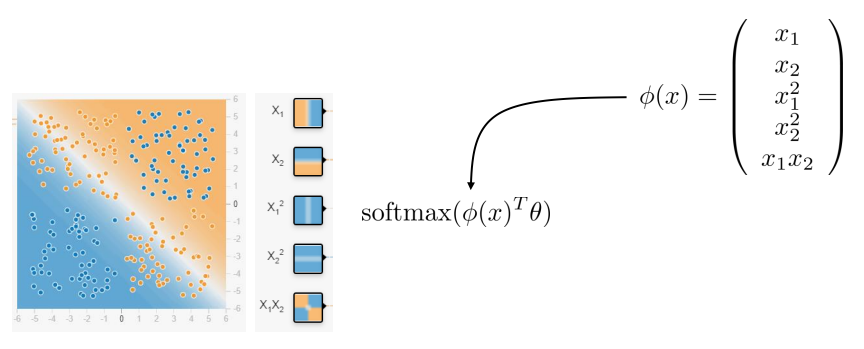
굳이 그럴 필요는 없습니다. 새로운 모델 대신 새로운 특성을 찾으면 됩니다.
새로운 특성을 학습을 통해 찾기
하지만 모든 과제마다 그에 맞는 특성을 찾아내는건 간단한 일이 아닙니다. 어떤 특성 공학이 주어진 과제에 적합한지는 실제로 실험해보지 않는 이상 알 수 없습니다. 이는 마치 머신러닝이 나오기 이전에 사람들이 직접 데이터간의 관계를 찾아 프로그램을 만들었던 일과 비슷해보입니다.
결과 라벨값을 예측하는 방법을 학습을 통해 찾았던 것처럼 새로운 특성도 학습을 통해 찾아볼 수 있지 않을까요? 모델이 새로운 규칙을 학습하기 위해 그 규칙에 파라미터를 추가했듯이, 새로운 특성을 학습하기 위해 특성에 파라미터를 추가해봅시다.
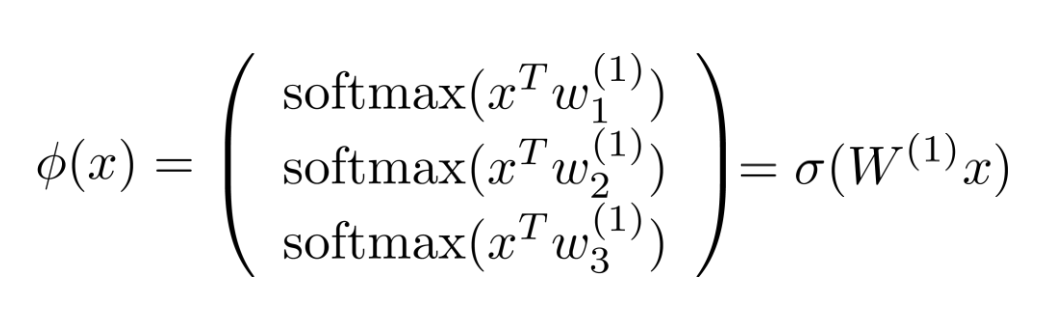
이렇게 입력 데이터
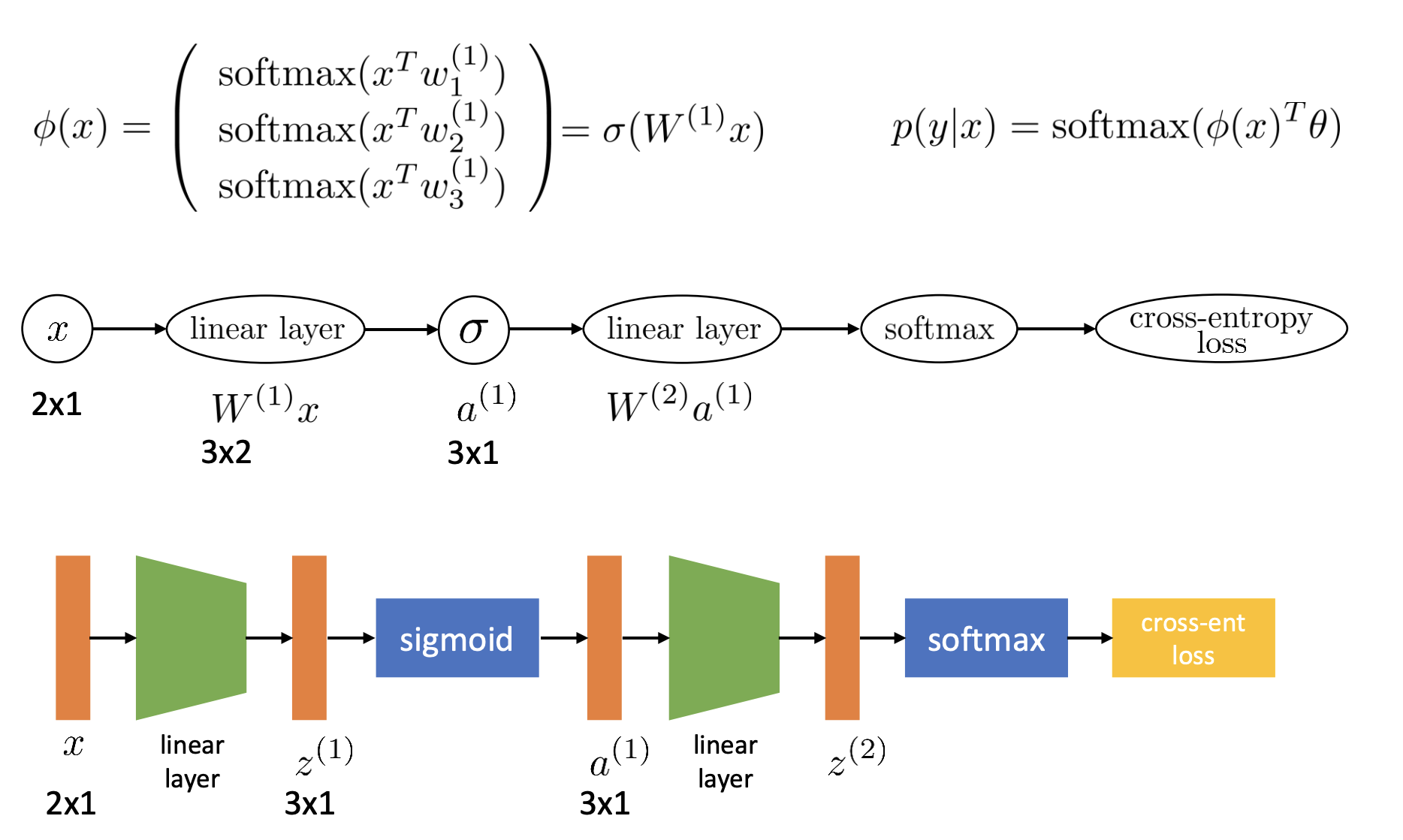
이제 모델은 더 복잡한 데이터에서 필요한 특성을 스스로 뽑아내 분류할 수 있게 되었습니다. 하지만 모델의 구조에서 보면 사실 기존 모델에 linear layer와 sigmoid라는 두 레이어가 추가됐을 뿐입니다. 간단히 말해, 모델이 더 복잡한 데이터를 처리하려면 특성을 뽑아내는 레이어를 추가하기만 하면 된다는 것입니다.
모델을 깊이 쌓는다는 의미
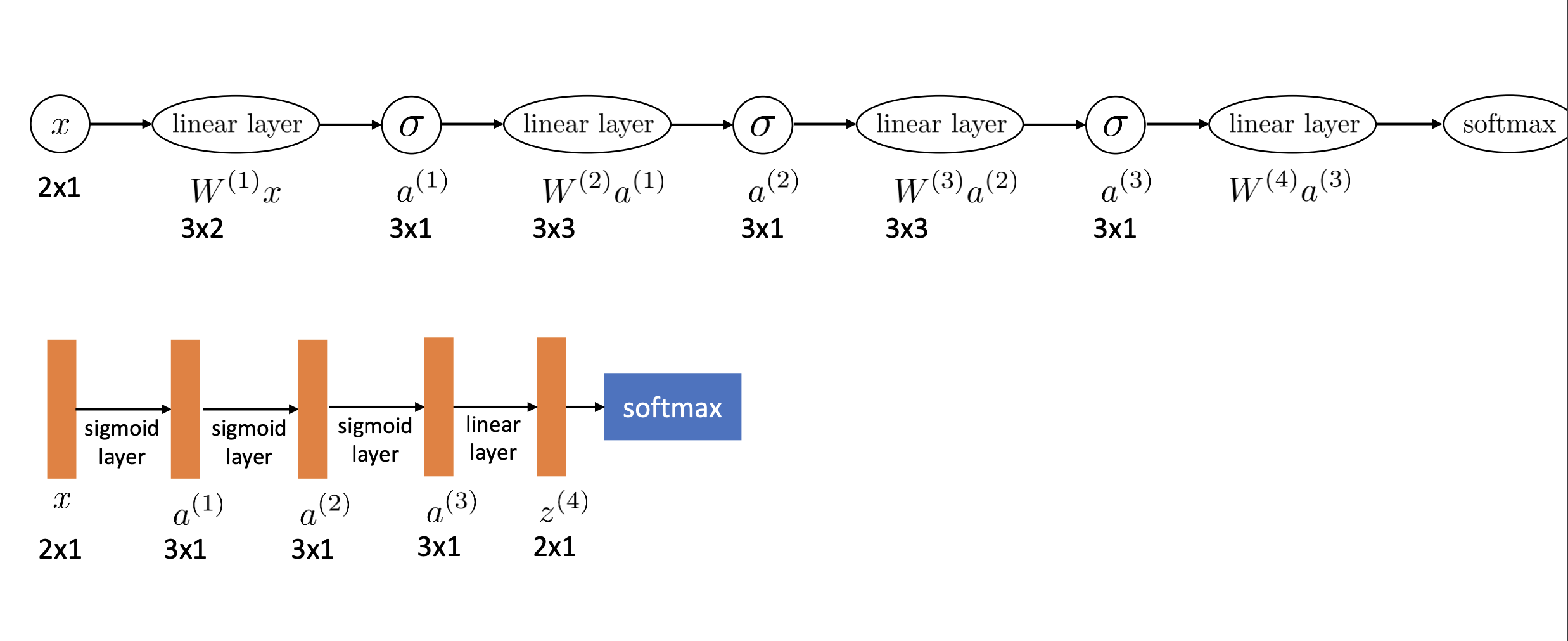
이제는 더 복잡한 데이터를 처리한다면 이제 linear layer와 sigmoid를 앞에 계속 추가하면 됩니다. 그러면 첫번째 레이어는 입력 이미지에서 어떤 특성을 뽑아낼 것이고, 그 다음 레이어는 추출된 특성들을 조합해 또다른 특성들을 얻어낼 겁니다. 그렇게 레이어를 거듭 지나가면서 추출된 특성들은 점점 추상적인 의미를 지니게 될 겁니다.
만약 주어진 이미지의 피사체가 어떤 동물인지 구분하는 모델이라면 첫번째 레이어는 이미지의 윤곽선만을 인식하지만, 두번째 레이어는 파악한 윤곽선들을 조합해 추상적인 도형이나 패턴을 읽게 되고, 그 다음 레이어는 눈이나 코, 입과 같은 동물의 일부분을 인식하게 됩니다. 이렇게 이미지나 텍스트, 음향 같은 복잡한 데이터도 레이어를 여러 층으로 쌓아 올린다면 사람처럼 추상적인 의미를 읽어낼 수 있게 됩니다. 이것이 딥러닝, 특히 신경망 모델이 주목을 받는 이유입니다.
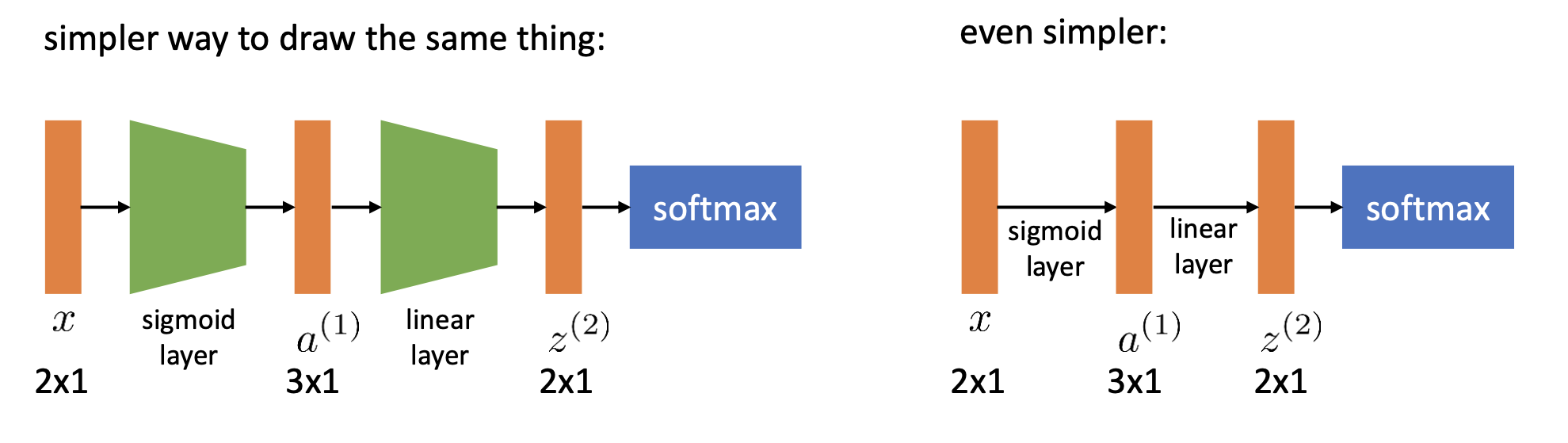
참고로 위의 그림처럼 신경망에서 linear layer + sigmoid와 같은 방식으로 자주 쓰이는 레이어 조합들이 있습니다. 그래서 보통 linear layer와 sigmoid를 하나로 합쳐 sigmoid layer처럼 하나로 합쳐서 표현할 겁니다.
활성화 함수
그런데 여기서 의문이 하나 생깁니다. linear layer는 특성을 만들기 위해서 선형결합을 하는 곳이기 때문에 필요하지만, sigmoid는 왜 필요한건지 알 수 없어 보입니다. 그렇다면 sigmoid 함수 말고 다른 함수는 안될까요? 무엇보다 linear layer로만 넣으면 안될까요?
그렇다면 한번 sigmoid layer를 빼고 linear layer만 넣어봅시다.
sigmoid layer를 빼보니 결국 하나의 linear layer로 합쳐진 모습을 볼 수 있습니다. 그렇다면 linear layer만 모델을 만든다면 결국 linear layer 하나와 성능이 동일하게 됩니다.
이는 sigmoid 대신 어떤 선형 함수를 넣더라도 똑같은 현상이 발생합니다. 이는 선형 함수의 특성때문에 발생합니다. 결국, 여러 레이어로 쌓아올려도 모델의 표현력을 유지하기 위해서는 linear layer 사이에 sigmoid와 같은 비선형 함수를 집어넣어야 합니다. 그리고 이렇게 추가된 비선형 함수를 활성화 함수(activation function) 라 부릅니다.
활성화 함수는 비선형 함수라면 어떤 것이든 사용해도 됩니다. 실제로 자주쓰이는 활성화 함수로 sigmoid, tanh, ReLU 등이 있습니다.
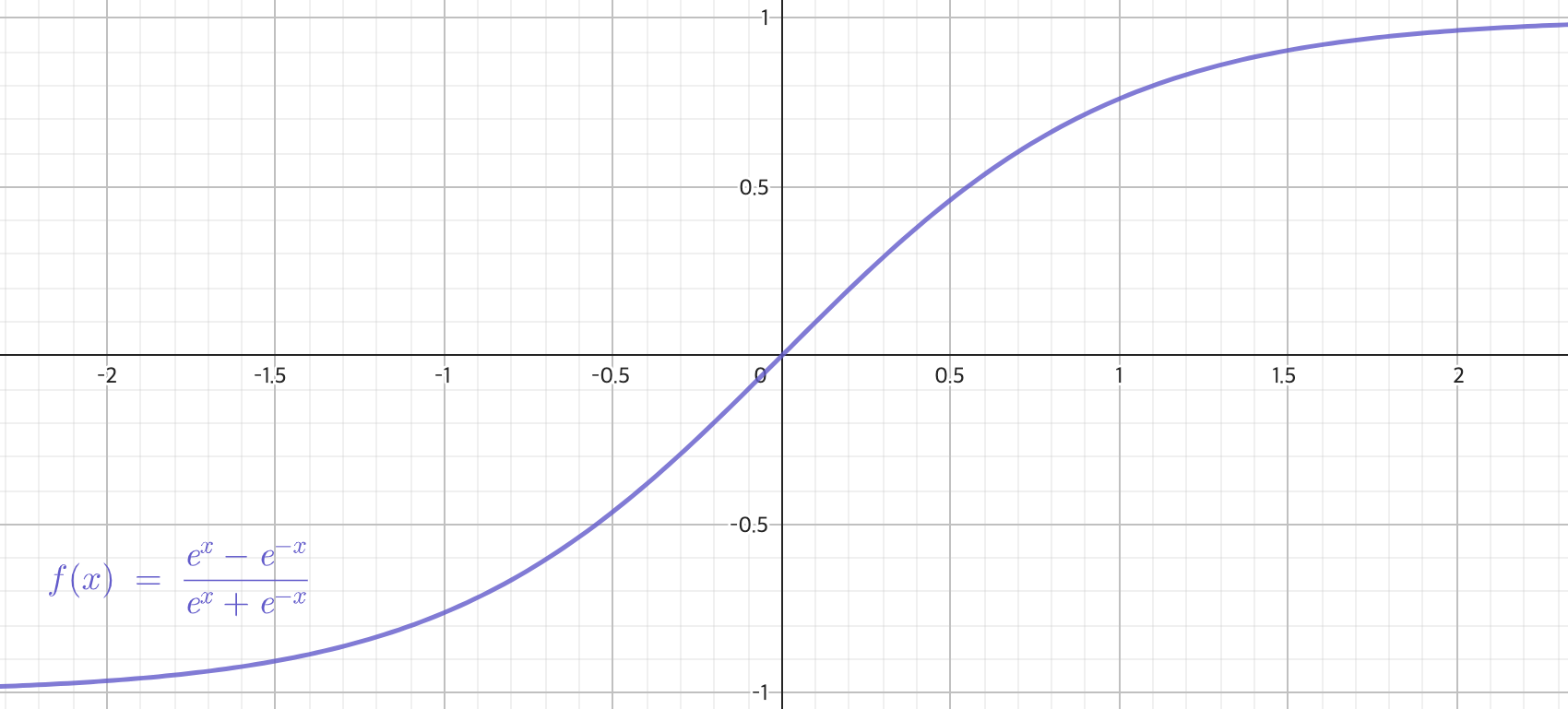
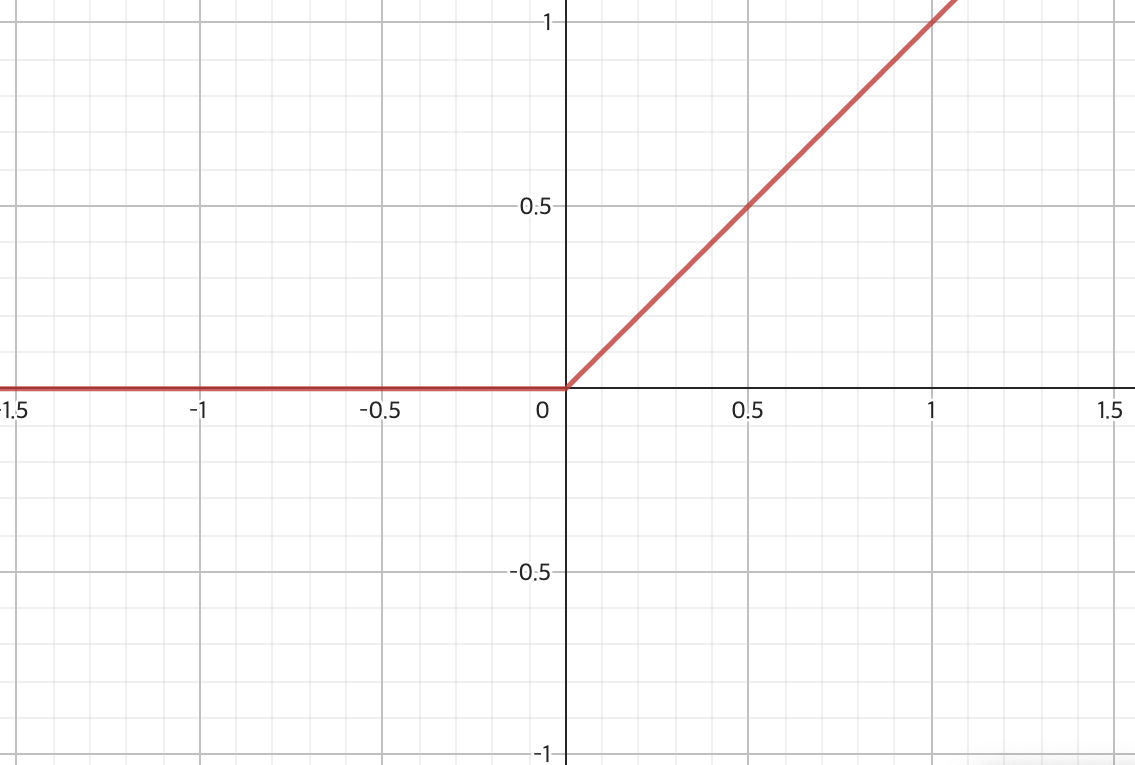
가중치와 편향
우리는 지금까지 linear layer에서 파라미터
다음과 같은 신경망 모델을 생각해봅시다. 만약에
이러한 문제를 해결하기 위해서는 보통 linear layer에 파라미터를 다음과 같이 추가합니다.
이전 모델과 비교해보면 linear layer에
linear layer에 편향을 추가하면 가중치와 곱해져서 0이 나오더라도 그 다음 레이어에서 입력값 때문에 결과값이 0이 될 가능성이 줄어듭니다. 그러면 우리는 예측 결과값이 0이 나오더라도 좀 더 신뢰할 수 있으며 학습시에 파라미터에 명확한 피드백이 전달됩니다.
신경망 훈련하기
머신러닝 구성요소 살펴보기
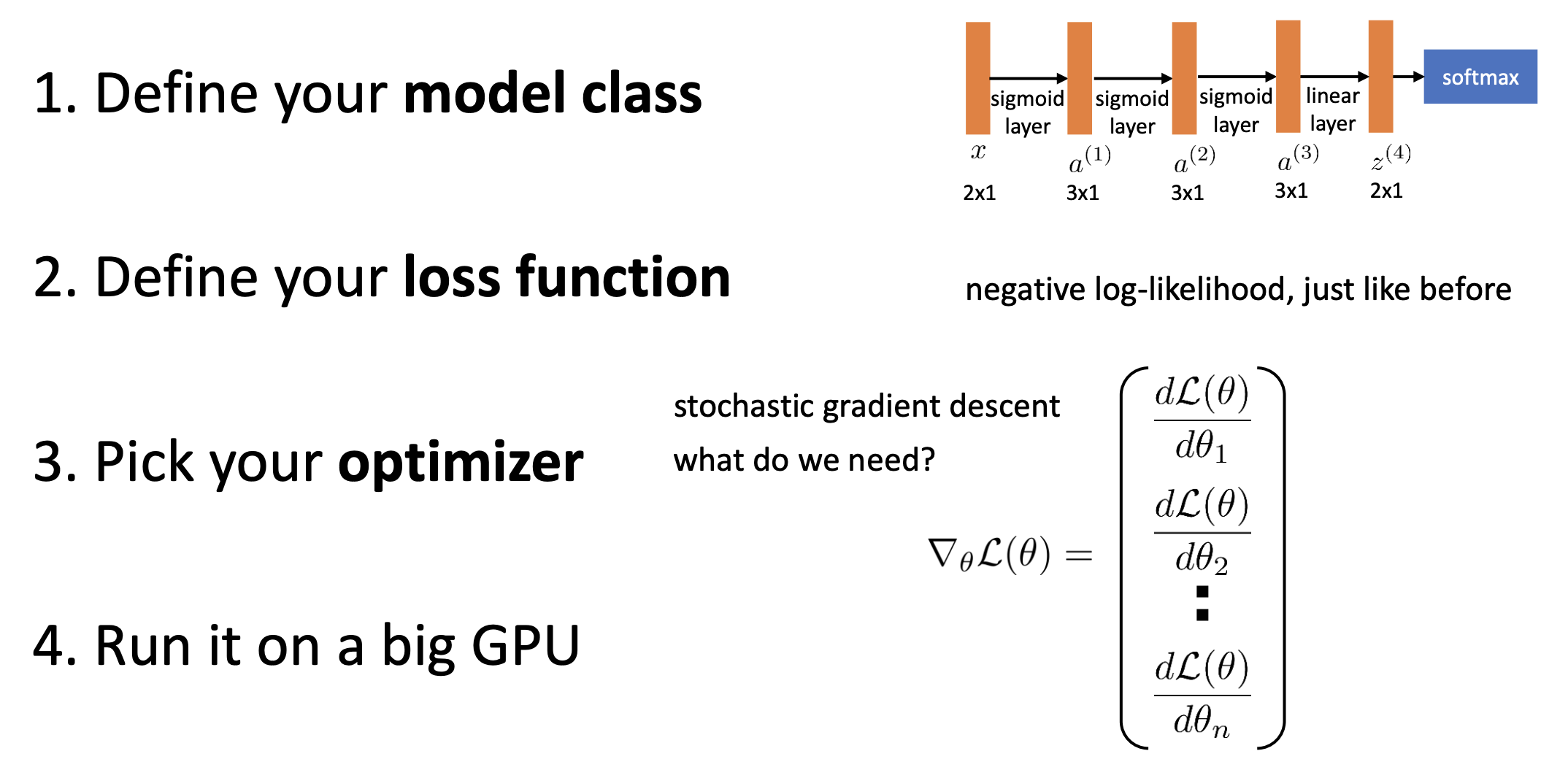
이제 신경망 모델을 학습시켜보겠습니다. 이전 강의에서 살펴봤듯이 머신러닝 모델을 학습시키기 위해서는 모델, 손실 함수, 옵티마이져 세가지가 필요합니다. 여기서 모델은 우리가 앞에서 본 신경망 모델이 될 것이고, 손실 함수 또한 기존에 사용한 NLL을 그대로 사용할 겁니다. 그리고 옵티마이져도 이전 강의에서 본 확률적 경사 하강법을 사용할 겁니다.
하지만 여기서 문제가 발생합니다. 확률적 경사 하강법을 사용하려면
신경망에서 그래디언트를 계산하기
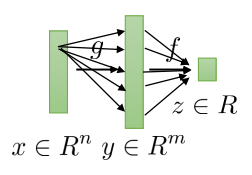
이전 쳅터에서 깊은 신경망 모델의 구조에 대해 설명했습니다. 신경망 모델은 일종의 여러 함수의 합성으로 볼 수 있습니다. linear layer를 함수
결국 합성 함수이니 각
하지만 걱정되는 부분이 한가지 있습니다. 고등학교 미적분에서 연쇄법칙을 배우긴 하지만 이는 일변수 함수일 때입니다. 하지만 우리가 미분해야 하는 함수는 다변수 함수입니다.
다변수함수의 연쇄법칙
다변수함수의 연쇄법칙을 살펴보기 위해 몇가지를 가정해보겠습니다.
두 함수
이제
그러면 벡터
여기서 특이한 점은 미분계수를 벡터로 표현한 점입니다. 이는 각 정의역과 공역에 해당하는 벡터 요소끼리의 조합마다 미분을 한 결과를 보여줍니다. 이러한 행렬을 자코비안 행렬(Jacobian matrix) 라고 합니다. 이처럼 다변수함수의 미분계수는 자코비안 행렬로 표현합니다.
이제 다변수함수의 연쇄법칙은 우리가 알고있는 연쇄법칙을 그대로 적용하면 됩니다.
참고로 우리가 구한건
주의할 점으로 자코비안 행렬에서 행과 열 중 어느 부분이 정의역 부분인지는 표기하는 사람마다 다를 수 있습니다. 다만 행렬곱을 수행할 수 있도록 일관성있게 표기하기 때문에 잘 살펴보면 알 수 있습니다.
연쇄법칙으로 신경망 그래디언트 계산하기
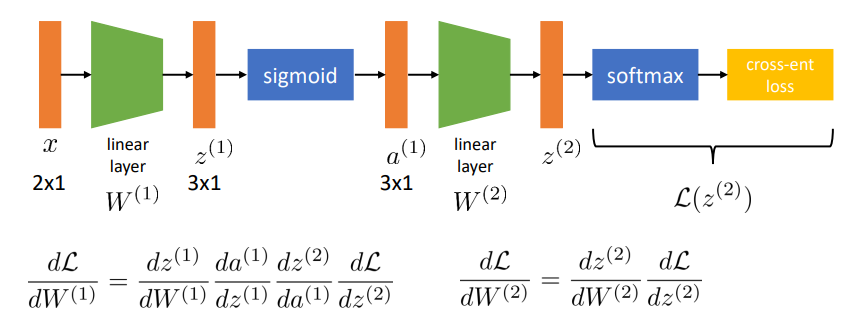
이제 신경망의 각 레이어마다 존재하는 파라미터
다변수함수의 그래디언트 계산할때 발생하는 문제
하지만 신경망의 그래디언트를 그대로 구하면 두가지의 문제가 발생합니다. 첫번째 문제로, 이대로 계산한다면 한번 그래디언트를 계산하는데 매우 오래 걸린다는 겁니다.
또 다른 문제는 이미 구한 값을 또 한번 계산해야한다는 점입니다.
여기서
하지만 이를 실제로 구현해보면 오히려 비효율적임을 알 수 있습니다. 미분계수를 구할때
역전파 알고리즘
이 두가지 문제를 해결하는 방법은 매우 간단합니다. 그저 순서를 반대로 하면 됩니다.
먼저 한 파라미터에 대한 그래디언트를 계산할 때 입력단 레이어부터 계산하지 않고 손실 함수 부분부터 계산합니다. 다시 말해,
그리고 입력단에서 가장 가까운 레이어의 파라미터부터 구하지 않고 손실 함수와 가장 가까운 파라미터부터 구합니다. 간단히 말해,
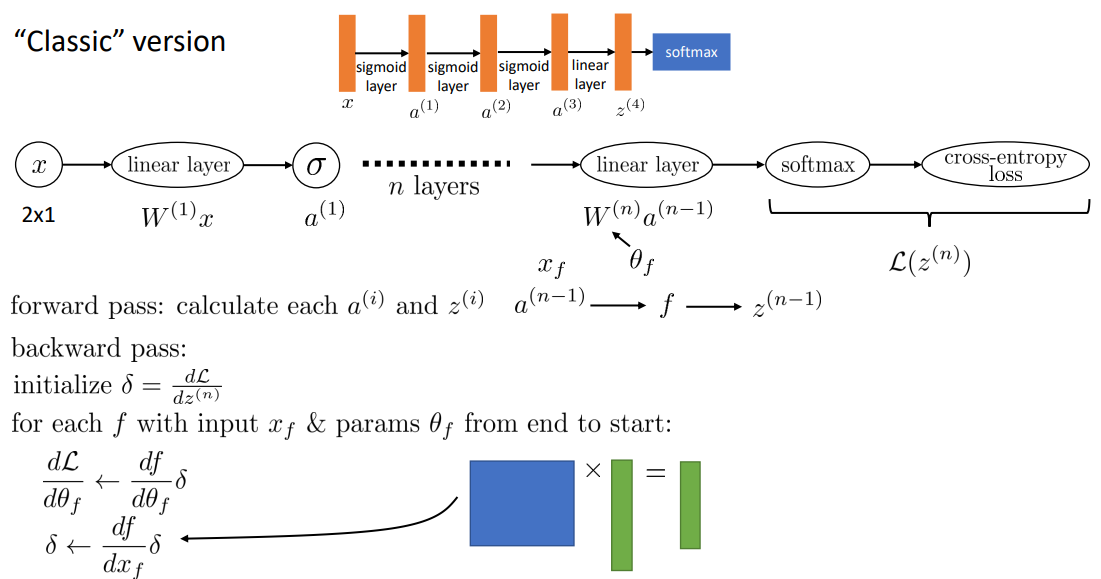
이 두가지 방법을 이용해 효율적으로 깊은 신경망의 그래디언트를 구하는 알고리즘을 역전파 알고리즘(Backpropagation algorithm)입니다. 입력값이 첫 레이어에서 손실함수까지 도달하는 순방향과 반대 방향으로 그래디언트를 계산하기 때문에 붙은 이름입니다.
역전파 알고리즘은 다음 순서를 따릅니다.
- 손실 함수에서 시작해서
- 다음 레이어로 건너가
- 입력단에 도달할 때까지 2~3을 반복합니다
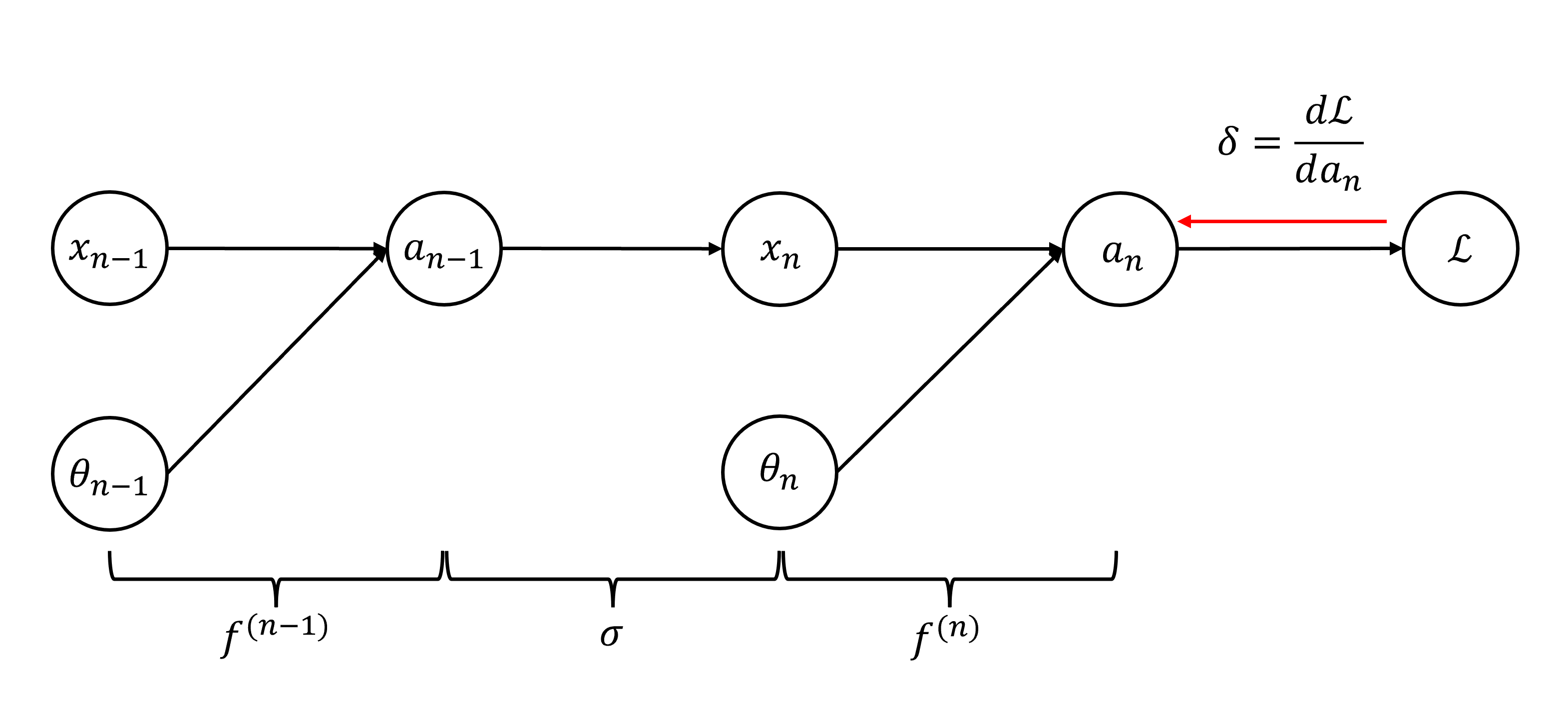
다음은 역전파 설명을 위해 간략하게 그린 신경망의 계산 그래프 입니다. 역전파 알고리즘은 먼저 손실 함수에서 시작해
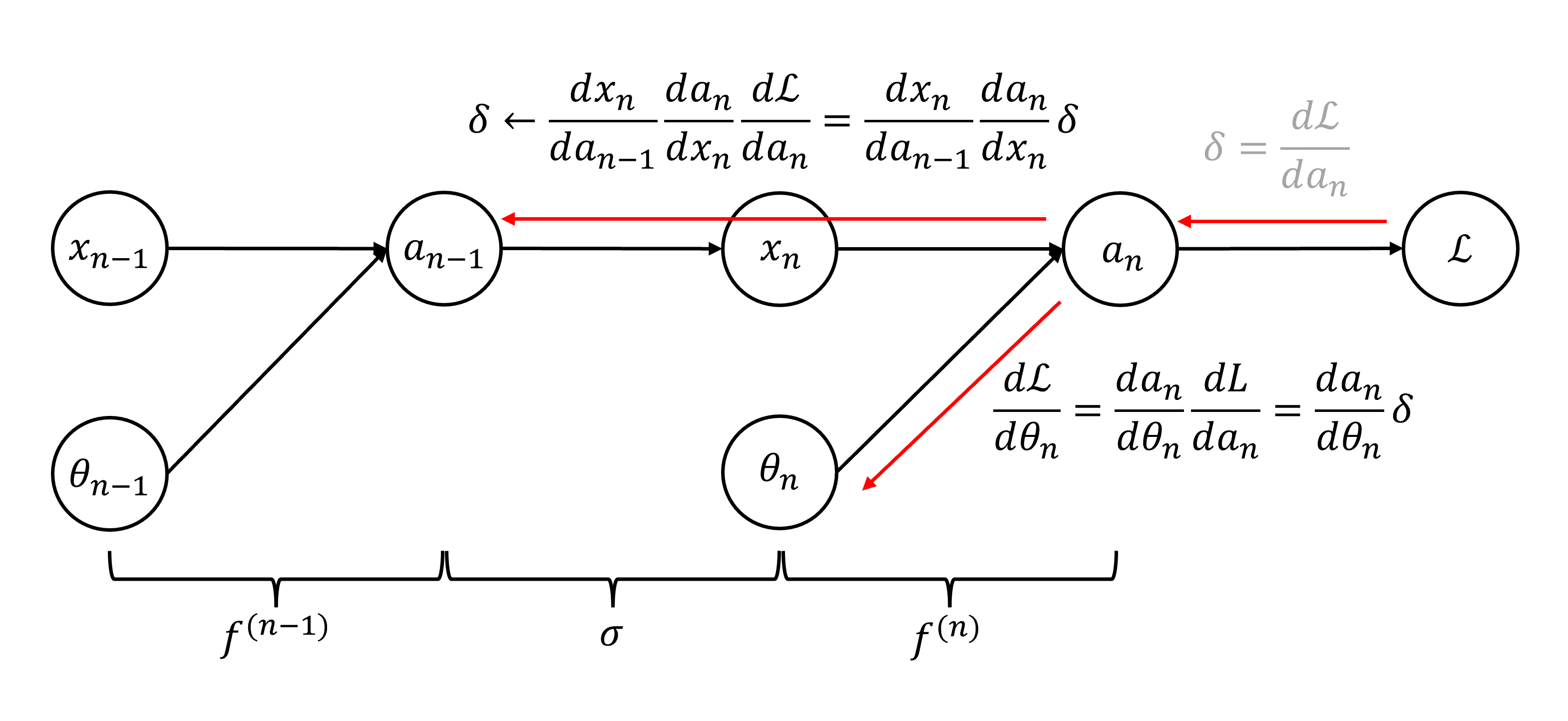
그런 다음
이제 다음 레이어 계산을 위해
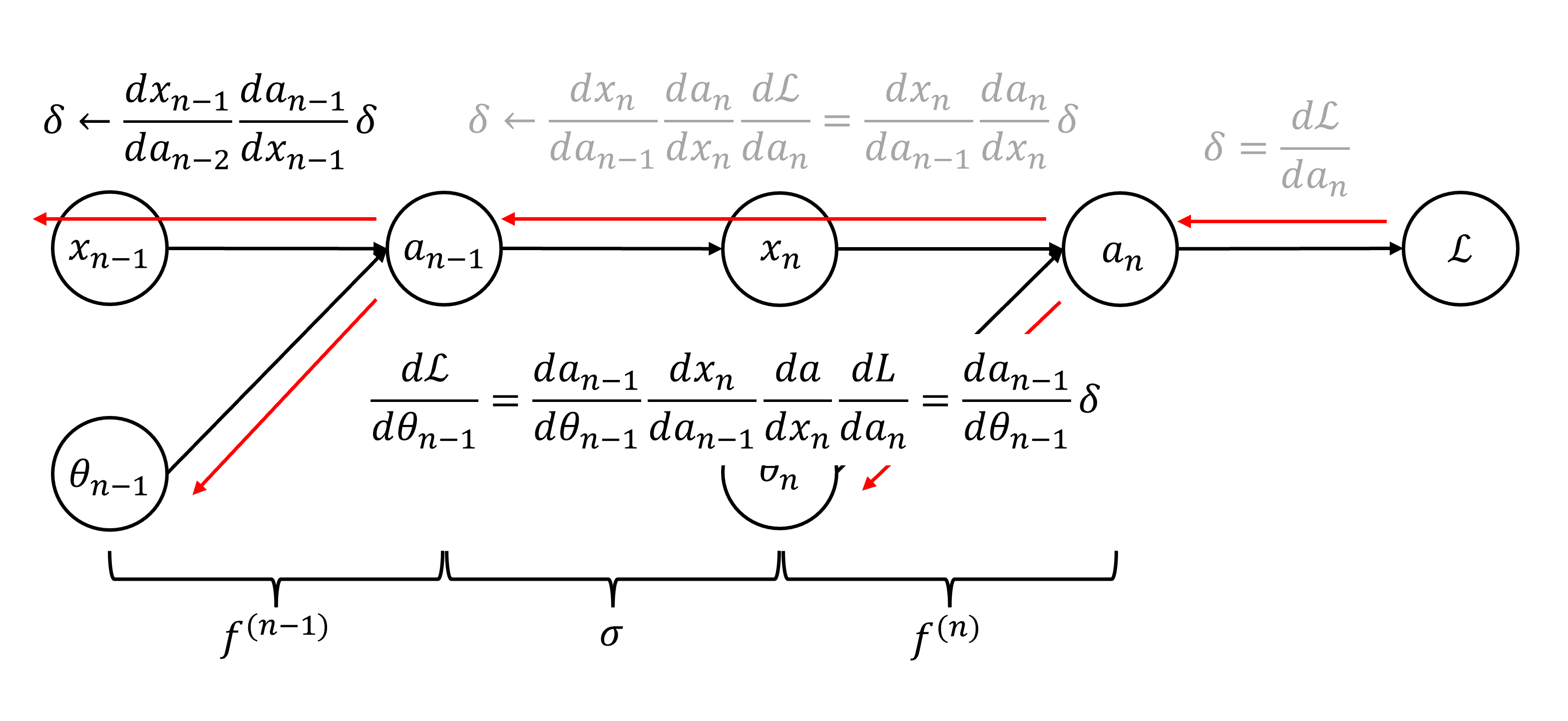
이제 다음 레이어에 도달한 다음 위의 과정을 똑같이 반복하면 됩니다. 이렇게 하면 연산 속도도 빠르면서 이미 계산한 값을 최대한 재활용하기 때문에 깊은 신경망은 역전파 알고리즘으로 그래디언트를 계산합니다.
신경망에서 역전파 알고리즘 적용해보기
이제 linear layer와 sigmoid에서 역전파 알고리즘이 어떻게 적용되는지 확인해봅시다.
Linear layer
먼저
먼저
자코비안 행렬로 구할때 이렇게 복잡해지는 이유는
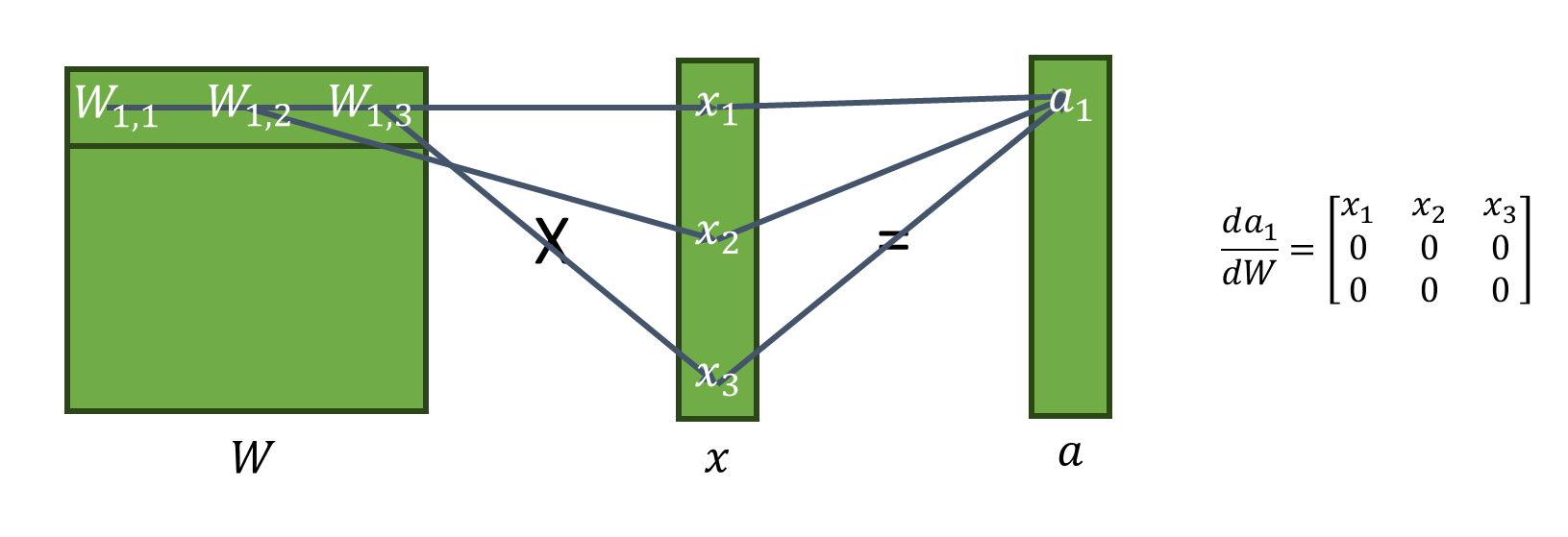
실제로 행렬곱 연산을 보면
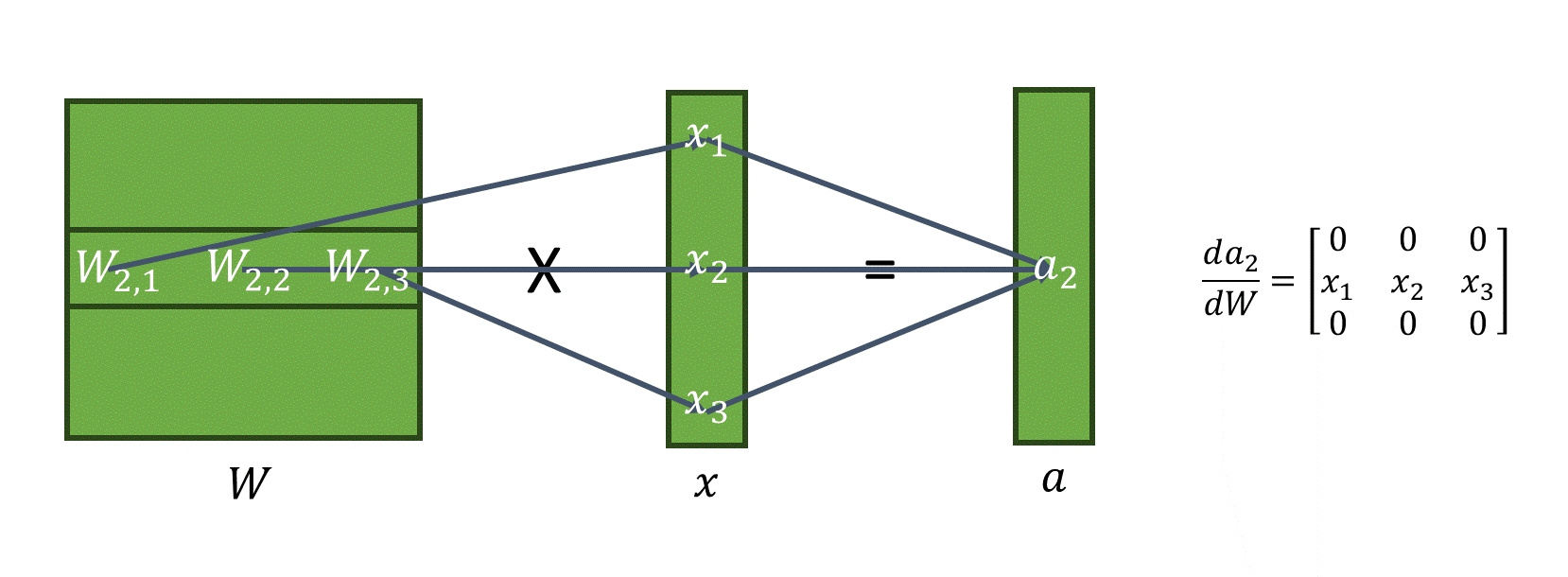
이러한 모습은
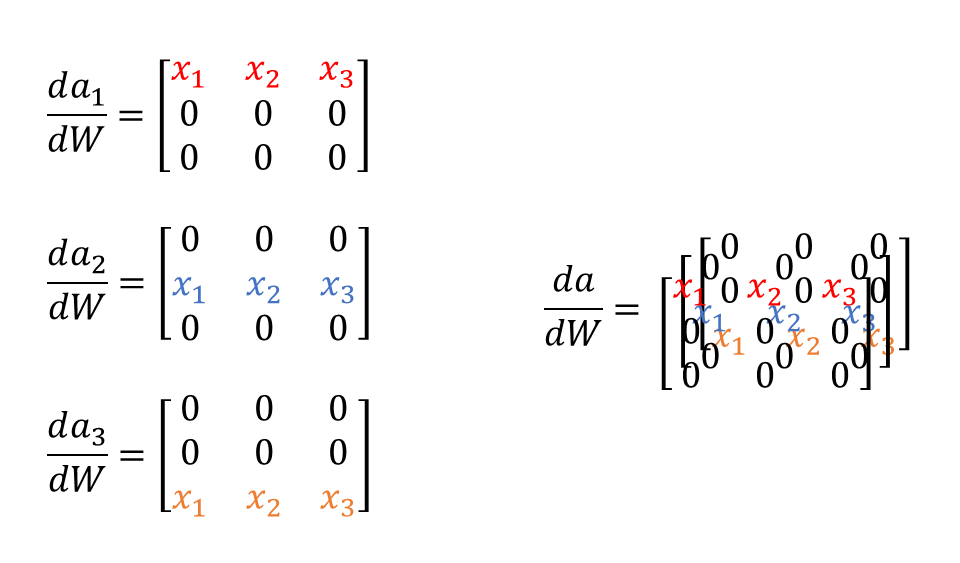
이제
Sigmoid function

sigmoid function은 파라미터가 없기 때문에
sigmoid function은 벡터의 각 차원마다 따로 적용되기 때문에 대각선 위치에 있는 요소가 아니면 모두 0입니다. 그리고 대각선에 있는 값들은
ReLU function
추가적으로 ReLU function의 경우에는 어떻게 구하는지 알아봅시다. ReLU는
ReLU는