![[TFX 스터디] 4. Transform cont.](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FWiRTV%2Fbtsz6Qiz91p%2FPdjhmhckXNmOMRSFgqCP90%2Fimg.png)
저번에 실패했던 preprocess_fn에 tokenizer 넣기에 성공했다. 막상해보니 간단한 일에 시간을 많이 소비했다는 생각이 들었다. 저번 스터디에서 발생했던 에러는 다음과 같다.
TypeError: Expected Tensor, SparseTensor, RaggedTensor or Operation got {'input_ids': <tf.Tensor 'Identity_1:0' shape=(1, 24) dtype=int32>, 'attention_mask': <tf.Tensor 'Identity_0' shape=(1, 24) dtype=int32>} of type <class 'transformers.tokenization_utils_base.BatchEncoding'>
처음에는 해당 에러가 어디서 발생했는지 알 수 없었다. 하지만 Huggingface의 Transformers를 써봤다면 익숙한 이름이 보일 것이다.
{'input_ids': <tf.Tensor 'Identity_1:0' shape=(1, 24) dtype=int32>, 'attention_mask': <tf.Tensor 'Identity_0' shape=(1, 24) dtype=int32>}
이는 Tokenizer가 문장을 토큰화한 결과를 내보낼때의 형식이다. input_ids에는 토큰화와 정수화가 이루어진 시퀀스가 담기고, attention_mask에는 모델에게 전달할 padding mask를 나타낸다. 그러자 다음 코드의 문제가 무엇이였는지 바로 알 수 있었다.
outputs['en_xf'] = tokenizer(en,
padding=True,
truncation=True,
max_length=512,
return_tensors="tf",
)
outputs['ko_xf'] = tokenizer(ko,
padding=True,
truncation=True,
max_length=512,
return_tensors="tf",
)
outputs에 들어갈 value들은 모두 텐서로 들어가야한다. 하지만 나는 지금까지 텐서가 담긴 딕셔너리를 집어넣고 있었다. 그래서 아까와 같은 TypeError가 발생한 것이다. 원인을 알았으니 코드를 다음과 같이 고쳤다.
output_en = tokenizer(en,
padding=True,
truncation=True,
max_length=512,
return_tensors="tf",
)
output_ko = tokenizer(ko,
padding=True,
truncation=True,
max_length=512,
return_tensors="tf",
)
outputs['en_seq_xf'] = tf.cast(output_en['input_ids'], dtype=tf.int64)
outputs['en_att_xf'] = tf.cast(output_en['attention_mask'], dtype=tf.int64)
outputs['ko_seq_xf'] = tf.cast(output_ko['input_ids'], dtype=tf.int64)
outputs['ko_att_xf'] = tf.cast(output_ko['attention_mask'], dtype=tf.int64)
여기서 tf.cast를 하는 이유는 tfx에서 정수값을 저장할 때는 무조건 tf.int64로 저장해야하기 때문이다. Tokenizer에서 반환하는 텐서의 dtype이 int32이기 때문에 이를 int64로 변환한 것이다.
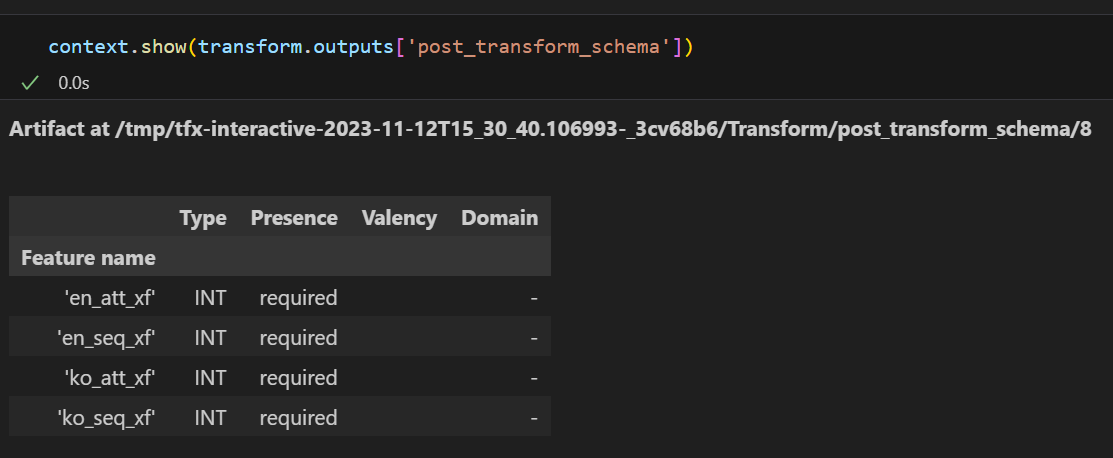
이제서야 가장 보고싶었던 결과가 나왔다. preprocess_fn에서 등장하는 값들의 타입만 제대로 확인했다면 바로 고쳤을 내용이였기에 다음부터는 더욱 타입 체크에 신경써야겠다.
def create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str, metadata_path: str) -> tfx.dsl.Pipeline:
example_gen = FileBasedExampleGen(
input_base=data_root,
custom_executor_spec=executor_spec.BeamExecutorSpec(JsonExecutor)
)
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples']
)
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics']
)
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=os.path.abspath('pipelines/transform.py'),
)
components = [
example_gen,
statistics_gen,
schema_gen,
transform,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pileline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata.sqlite_metadata_connection_config(metadata_path),
components=components,
)
tfx.orchestration.LocalDagRunner().run(
create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
metadata_path=METADATA_PATH,
)
)
그리하여 오랜만에 pipeline 코드를 업데이트 했다. transform 다는데 생각보다 오랜 시간이 걸렸다. 이제 모델 학습 부분을 빠르게 진행해야겠다.
'인공지능 > Tensorflow Extended' 카테고리의 다른 글
| [TFX 스터디] 3. Transform (0) | 2023.10.31 |
|---|---|
| [TFX 스터디] 2. Interactive Notebook (0) | 2023.10.13 |
| [TFX 스터디] 1. ExampleGen 컴포넌트 추가하기 (1) | 2023.10.08 |
| [TFX 스터디] 0. TFX를 활용하는 프로젝트 시작 (0) | 2023.09.24 |
| [살아 움직이는 머신러닝 파이프라인 설계] 11. 파이프라인 1부 & 12. 파이프라인 2부 (0) | 2023.09.17 |