![[TFX 스터디] 1. ExampleGen 컴포넌트 추가하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbxUL36%2Fbtsxp8Z39Xg%2FHk9UV9lTakrpg7flo72ct0%2Fimg.png)
사용할 데이터셋 준비하기
데이터셋은 AI Hub의 일상생활 및 구어체 한-영 번역 병렬 말뭉치 데이터를 사용했다.
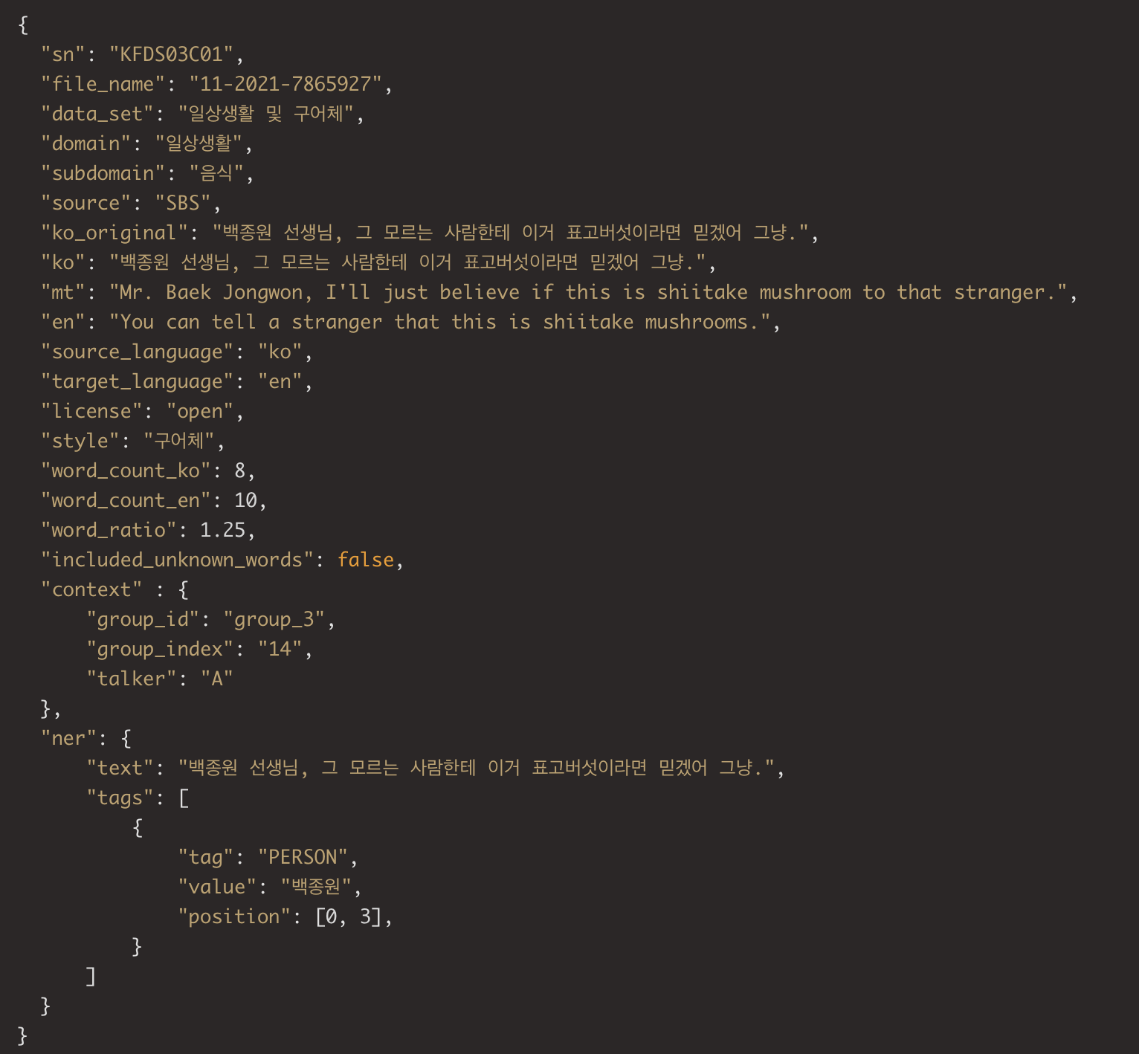
꽤 많은 양의 데이터를 무료로 얻을 수 있다는 점은 매우 좋았지만, 한가지 문제점이 있었다.

TFX가 기본적으로 지원하는 파일 타입에 JSON이 없다. 다행이도 JSON 파일을 읽고 tf.Example로 변환하는 ExampleGen을 편하게 만들 수 있다.
# pipelines/pipeline.py
import tfx.v1 as tfx
from tfx.components.example_gen.component import FileBasedExampleGen
from tfx.dsl.components.base import executor_spec
from pipelines.custom_executor.json_executor import Executor as JsonExecutor
# ...
example_gen = FileBasedExampleGen(
input_base=data_root,
custom_executor_spec=executor_spec.BeamExecutorSpec(JsonExecutor))TFX에서 Executor부분만 커스텀하면 파일을 읽고 데이터셋을 만드는 ExampleGen을 선언할 수 있다.
# pipelines/custom_executor/json_executor.py
class Executor(BaseExampleGenExecutor):
def GetInputSourceToExamplePTransform(self) -> beam.PTransform:
return _JsonToExample여기서 Executor를 만들때 Beam Pipeline을 통해 입력 데이터를 레코드로 만들어줄 beam.PTransform 함수를 하나 만들어주어야 한다. 그 다음에 GetInputSourceToExamplePTransform 함수를 통해 전달하면 된다.
# pipelines/custom_executor/json_executor.py
@beam.ptransform_fn
@beam.typehints.with_input_types(beam.Pipeline)
@beam.typehints.with_output_types(tf.train.Example)
def _JsonToExample(
pipeline: beam.Pipeline, exec_properties: Dict[str, Any], split_pattern: str) -> beam.pvalue.PCollection:
"""
"""
input_base_uri = exec_properties[standard_component_specs.INPUT_BASE_KEY]
json_pattern = os.path.join(input_base_uri, split_pattern)
logging.info('Processing input json data %s to TFExample', json_pattern)
return (pipeline
| 'ReadFromTextFile' >> beam.io.ReadFromText(json_pattern)
| 'ConvertToJson' >> beam.Map(json.loads)
| 'ToTFExample' >> beam.Map(_DictToExample)
)위의 코드는 beam.PTransform 함수를 정의하는 부분인데, 데코레이터가 3개나 된다. @beam.ptransform_fn는 해당 함수가 ptranform 함수로 변환해주고, 나머지 @beam.typehints.with_input_types과 @beam.typehints.with_output_types는 이름에서도 알 수 있듯이 입력 타입과 출력 타입을 정의한다.
또한 return 부분을 보면 꽤 특이한 expression이 보이는데 해당 부분이 Beam Pipeline에서 데이터가 어떻게 순차적으로 처리되는지를 정의한 것이다. 각 단계는 | 연산자를 통해 연결되고, >> 연산자 뒤에 처리 함수를 둔다. >> 연산자 앞에 있는 문자열은 해당 과정에 붙이는 이름이다. 만약에 pipeline 처리중에 오류가 발생하면 붙여둔 이름을 통해 사용자에게 어느 과정에서 오류가 발생했는지를 알려준다.
_JsonToExample는 eadFromText를 통해 json 파일을 텍스트로 읽어오고, json 모듈을 통해 파이썬 딕셔너리로 변환한 후에, 각 샘플마다 tf.Example 타입으로 변환한다. 그런데 여기서 주의할 점은 ReadFromText를 통해 텍스트를 읽어오면 읽어온 텍스트를 각 line마다 처리하게 된다. 즉, beam.Map(json.loads)는 파일 전체를 받는게 아니라 각 line마다 따로 받고 처리하게 된다.
여기서 위에서 가져온 데이터셋을 처리하는데 문제가 발생했다. 가져온 json 파일은 위에서 보여준 레이블 예시처럼 사람이 읽기 편한 포멧으로 저장되어 있다. 그런데 pipeline에서 각 줄마다 함수에게 넘겨주다보니 json 객체를 읽을 수 없다. 그래서 ndjson처럼 각 줄마다 json 객체가 놓이도록 json 파일을 변환했다.
# utils/json2ndjson.py
import json
with open('./data/origins/train_en_ko.json', 'r') as f:
dat = json.load(f)
lst = dat['data']
with open('./data/train/train_en_ko.ndjson', 'w') as f:
for record in lst:
f.write(json.dumps(record) + '\n')이제 json 파일도 정리되었으니 마지막 과정인 tf.Example 변환 함수도 만들어야 한다.
# pipelines/custom_executor/json_executor.py
@beam.typehints.with_input_types(Dict[str, Any])
@beam.typehints.with_output_types(tf.train.Example)
def _DictToExample(record_dict: Dict[str, Any]) -> tf.train.Example:
def bytes_feature(value):
if isinstance(value, type(tf.constant(0))):
value = value.numpy()
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
ko_bytes = bytes(record_dict['ko'].encode('utf-8'))
en_bytes = bytes(record_dict['en'].encode('utf-8'))
ko_string = bytes_feature(ko_bytes)
en_string = bytes_feature(en_bytes)
return tf.train.Example(features=tf.train.Features(feature={
'ko': ko_string,
'en': en_string,
}))_JsonToExample과는 다르게 @beam.ptransform_fn가 없는데 사실 ptransform과 아닌 함수의 차이를 아직 잘 모르겠다. 추후에 알게되면 따로 정리할 예정이다.
json 데이터셋 파일에서 필요한 내용은 한국어 문장과 영어 문장이므로 각 문장을 BytesList로 변환하고 이들을 가지는 tf.Example를 만든다.
# pipelines/pipeline.py
def create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str, metadata_path: str) -> tfx.dsl.Pipeline:
example_gen = FileBasedExampleGen(
input_base=data_root,
custom_executor_spec=executor_spec.BeamExecutorSpec(JsonExecutor))
components = [
example_gen,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pileline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata.sqlite_metadata_connection_config(metadata_path),
components=components,
)
tfx.orchestration.LocalDagRunner().run(
create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
metadata_path=METADATA_PATH,
)
)이렇게 만든 ExampleGen을 Apache Beam에서 실행해보았다. 다행이도 오류없이 tf.Example로 잘 변환되었다. 다만 다음 컴포넌트에서 데이터셋이 정상적으로 전달되는지 아직 확인해보지 못했다. 다음주에 ExampleGen에서 가져온 데이터셋에서 통계와 스키마를 뽑아내는 StatisticsGen과 SchemaGen를 사용해 볼 것이다.
'인공지능 > Tensorflow Extended' 카테고리의 다른 글
| [TFX 스터디] 3. Transform (0) | 2023.10.31 |
|---|---|
| [TFX 스터디] 2. Interactive Notebook (0) | 2023.10.13 |
| [TFX 스터디] 0. TFX를 활용하는 프로젝트 시작 (0) | 2023.09.24 |
| [살아 움직이는 머신러닝 파이프라인 설계] 11. 파이프라인 1부 & 12. 파이프라인 2부 (0) | 2023.09.17 |
| [살아 움직이는 머신러닝 파이프라인 설계] 10. 고급 TFX (0) | 2023.09.17 |